Overview
A state transport agency was deploying a new
Portal to provide commuters with a digital channel to view travel history and manage
transactions. While the vendor delivered functional development and system testing, the agency
required independent performance validation to ensure the portal could operate reliably at
scale.
DevOps1 proposed and executed a performance testing engagement to validate
baseline performance, peak capacity, concurrent processing, and
recovery behaviour. The approach used modern load testing tooling and integrated monitoring to
provide actionable insights, capacity limits, and remediation recommendations.
Challenges
The programme faced several performance and operational risks that needed
controlled validation before production launch:
- High concurrency requirements: design goal to support high number of concurrent users with
sub-second navigation for key journeys
- Complex external dependencies (payment gateways, API gateways, third-party services) and
rate limits that could affect testability and production behaviour
- Concurrent heavy processing: peak transaction loads occur simultaneously with large-scale
data ingestion and analytics jobs
- Production-like failure modes were untested (gateway timeouts, DB connection loss,
autoscaling limits), increasing risk of degraded user experience under stress
- Need for realistic, PCI-compliant synthetic data and safe test isolation to avoid impacting
production services
Solution
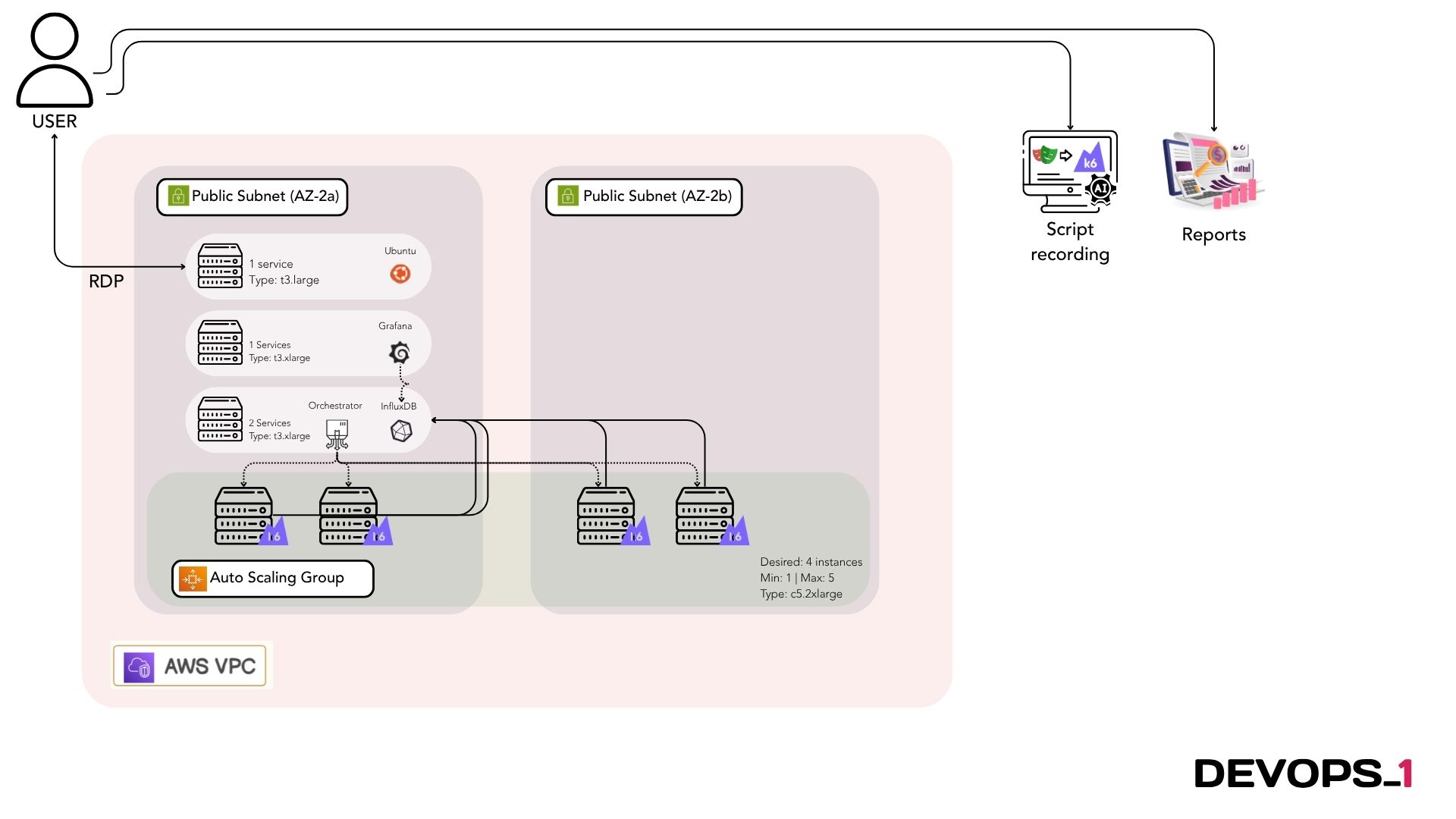
DevOps1 delivered a structured, four-scenario performance test program using
K6 as the core testing framework and a supporting monitoring stack for observability:
Primary activities
- Planning & environment preparation: test environment validation, traffic allowlisting, and
dependency mocking where appropriate
- Load testing (baseline): establish steady-state performance under average hourly production
load with a ramp-up, steady-state and ramp-down to characterise normal behaviour
- Stress testing (peak): exercise peak volume plus headroom to identify breaking points
and graceful degradation behaviour
- Volume testing (concurrent processing): validate behaviour when peak transactions coincide
with data ingestion and calculations pipelines
- Recovery/resilience testing: simulate service interruptions (DB disconnects,
gateway failures) while under load to measure recovery times and failure modes
Tooling & integration
- Load engine: K6 open-source scripts for distributed execution when required
- Monitoring & dashboards: Grafana, AWS CloudWatch
- Test data: PCI-compliant synthetic data
- Reporting: automated K6 reports plus executive dashboards summarising SLAs, bottlenecks and
remediation actions
Deliverables included the Performance Test Plan, K6 scripts for key user
journeys, test execution artefacts, detailed findings and a prioritised set of optimisation
recommendations.
Benefits
The engagement produced measurable outcomes that reduced launch risk and
improved operational readiness:
- Capacity validation: quantifiable throughput and concurrent user limits, enabling confident
capacity planning
- Bottleneck identification: clear diagnostics across middleware, DB, and external gateways
with targeted optimisation actions
- Improved resilience: recovery scenarios exercised and documented, with recommendations to
improve graceful degradation and autoscaling triggers
- Risk mitigation: secure synthetic test data and environment isolation ensured no impact to
production services during testing
- Decision-ready reporting: executive summary and technical remediation roadmap to prioritise
fixes and re-test criteria